
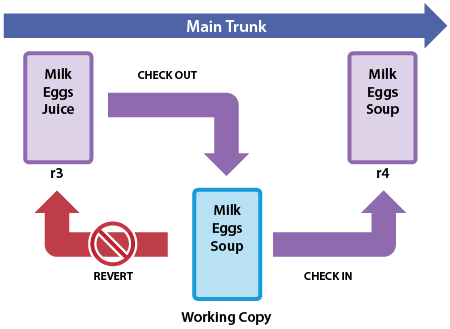
In this diagram above we have a simple file (revision 3) that contains the text "Milk Eggs Juice". The developer checks it out and modifies the working copy so it now contains "Milk Eggs Soup". This change may be checked in, in which case it becomes revision 4 in the VCS. Or, the change is reverted to revision 3 so that the working copy is now "Milk Eggs Juice". This is a simple concept but provides for a powerful paradigm that allows the developer much more freedom to try out changes knowing that it is, firstly, easy to revert and secondly, if the change is committed to the VCS that the exact changes made are recorded and can be reverted at any time in the future.
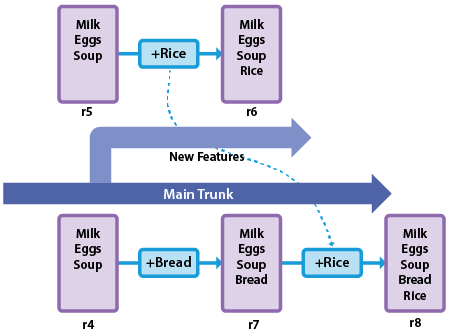
In this scenario, the main trunk is branched at revision 4 to create a parallel development (revision 5) for adding new features to the product whilst the Main Trunk continues with bug fixes being applied. The developer gets straight into it and adds in the new feature "Rice" which produces revision 6. This change waits until sometime in the future when a new release is required and the change will be merged back into the Main Trunk.
Meanwhile a bug is reported from the field so "Bread" is added and this change is issued as a bug fix. Clearly the customer does not receive the change for the new feature. It's been isolated from the released code.
The time comes to produce the next release so the new features are merged back to the Main Trunk adding "Rice" to the file and resulting in "Milk Eggs Soup Bread Rice". This is a semi-automated step. The system can make most changes accurately but where the same line has changed it will report conflicts and require that the conflict is resolved before the change can be committed into the VCS to create revision 8. This happens here because line 4 has been changed in both the Main Trunk and Branch. In this case the developer decided that both changes needed to stay with the new feature change added after the Main Trunk change.
Also See
Working with Tasks in the LANSA for i User Guide
